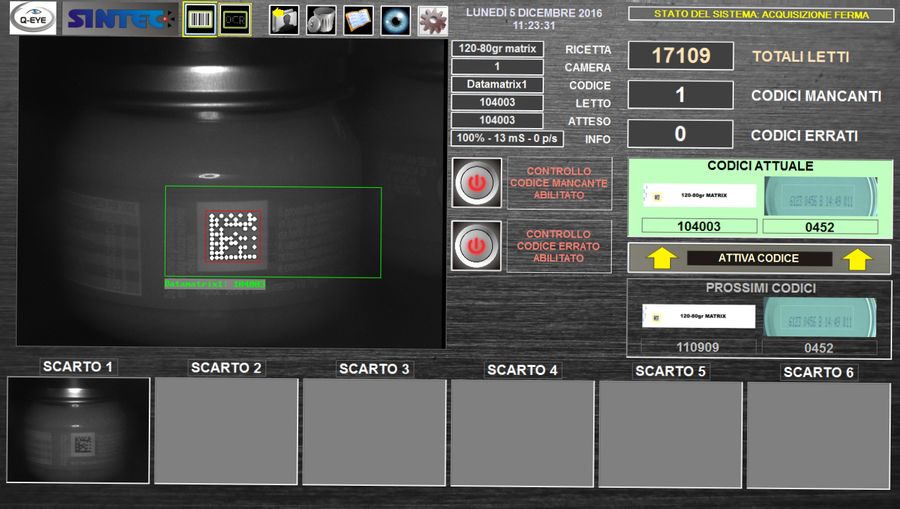
Our systems are able to read mono-dimensional (1D) and bi-dimensional (2D) codes. The first group is made of linear barcodes used to encode information through spaces and vertical lines. They are mainly used to represent short strings (e.g. the identification number for an item that can be found in a supermarket, or the part number for a replacement part). Some examples of this kind of code are EAN (8, 13, 14), GS1 (128, Databar), Pharmacode, UPC (A, E). Bi-dimensional codes can be divided in multi-line codes and matrices, representing information through blocks placed inside a predefined grid. This second group of codes is able to represent longer strings (like web and postal addresses but also identification data printed on badges or boarding passes). Among the 2D codes that our systems can read there are Aztec, Data Matrix, Maxicode, QR code and PDF147 (also in the micro and truncated variants).
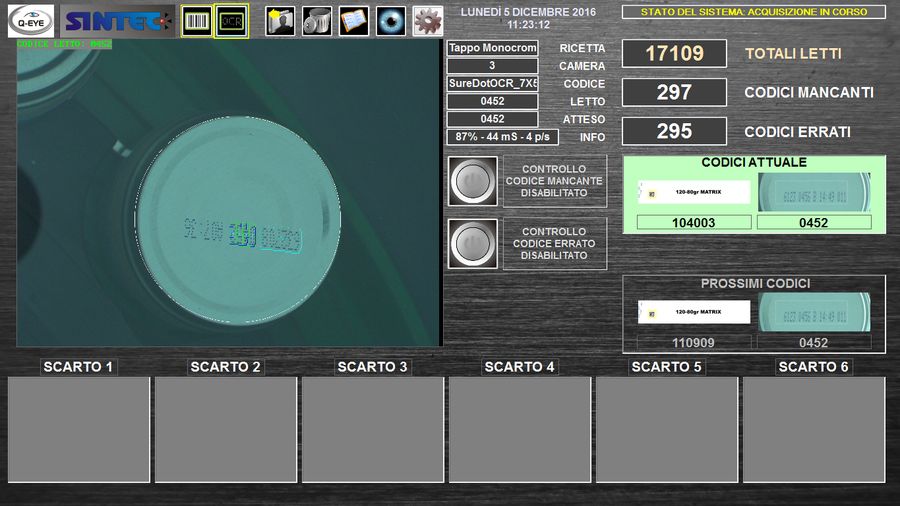
It’s also possible to perform optical character recognition (OCR) on dot-matrix-printed alphanumeric strings. Text can be even inspected directly on the finished product, for example on jars or boxes.
Moreover we can verify that prints faithfully reproduce the contents of a PDF file, extremely useful to ensure the correctness of manuals and other printed materials. Checks can be done on both the document faces, as well as on specific areas. The inspection can cover text, images, codes and we can detect the presence of printing defects like stains and non readable areas. It’s even possible to check inking details. Error detection can be tuned by setting different tolerance thresholds and on their crossing it’s possible to send the host machine a signal to handle the event. The image acquisition process can be shown in real-time on the monitor and in any case all the acquired information will be archived on a log file.
Our systems can reliably elaborate up to 100,000 readings per minute.
Some examples of readable elements: